void fast_copy(uint8_t *to, uint8_t *from, uint16_t count)
{
uint16_t n = (count + 7) / 8;
switch (count % 8) {
case 0: do { *to++ = *from++;
case 7: *to++ = *from++;
case 6: *to++ = *from++;
case 5: *to++ = *from++;
case 4: *to++ = *from++;
case 3: *to++ = *from++;
case 2: *to++ = *from++;
case 1: *to++ = *from++;
} while (--n > 0);
}
}起源于达夫设备,最初的需求是,一段起始地址为from,长度为count的数据,写入到一个内存映射的I/O(Memory Mapped I/O)寄存器to中。
最简单的拷贝
直接用for或者while循环就可以解决了,如下所示:
void send(uint8_t *to, uint8_t *from, uint16_t count)
{
do
{
*to = *from++;
}while (--count >0);
}如此简单的代码,为何说它性能低下呢?主要有两个问题:
"无用"指令太多
无法充分发挥CPU的ILP(Instruction-Level Parallelism)技术
无用指令
所谓无用指令,是指不直接对所期望的结果产生影响的指令。
对于这段代码,期望的结果就是把数据都拷贝到I/O寄存器to中。那么,对于这个期望的结果来说,真正有用的代码,其实只有中间那一行赋值操作:

而每次迭代过程中的while (--count > 0)产生的指令,以及每次迭代结束后的跳转指令,对结果来说都是无用指令。
上面最简单的实现中,每次循环迭代只拷贝一个字节数据。这就意味着,有多少个字节的数据,就需要执行多少次跳转和条件判断,以及--count的操作。
汇编代码:

x64上优先使用寄存器传递,对于send()函数,第一个参数to存放在寄存器rdi中,第二个参数from存放在rsi中,第三个参数count存放在寄存器edx中。
第2~7行,把三个参数分别压入栈中;
第9~14行,对应C语言的*to = *from++;
第15~19行,对应C语言的while (--count > 0);
最后几句,恢复栈帧并返回
所以,第9-19行属于热点路径,也就是主循环体。第9-14行属于有效指令,第15-19行对于期望的数据结果来说就是无用指令。
热点路径中,无用指令数占了整个热点路径指令数的一半,其开销也占到整个函数的50%!
无法充分发挥ILP技术优势
现代CPU为了提高指令执行的速度和吞吐率,提升系统性能,不仅一直致力于提升CPU的主频,还实现了多种ILP(Instruction-Level Parallelism 指令级并行)技术,如超流水线、超标量、乱序执行、推测执行、分支预测等。
一个设计合理的程序,往往能够充分利用CPU的这些ILP机制,以使性能达到最优。
但是,在代码热点路径上,无用指令太多,且每个迭代只执行一条*to = *from++,无法充分发挥ILP的技术优势。
循环展开
所谓循环展开,是通过增加每次迭代内数据操作的次数,来减小迭代次数,甚至彻底消除循环迭代的一种优化手段。
循环展开,有以下优点:
有效减少循环控制指令。这些指令,是对结果不产生影响的无用指令。减少这些指令,就可以减少这些指令本身执行所需的开销,从而提升整体性能。
通过合理的展开,可以更加有效地利用指令级并行ILP(Instruction-Level Parallelism 指令级并行)技术。
循环展开是一个很常用的性能优化手段,所有现代编译器,通过合适的选项,都支持循环展开优化。
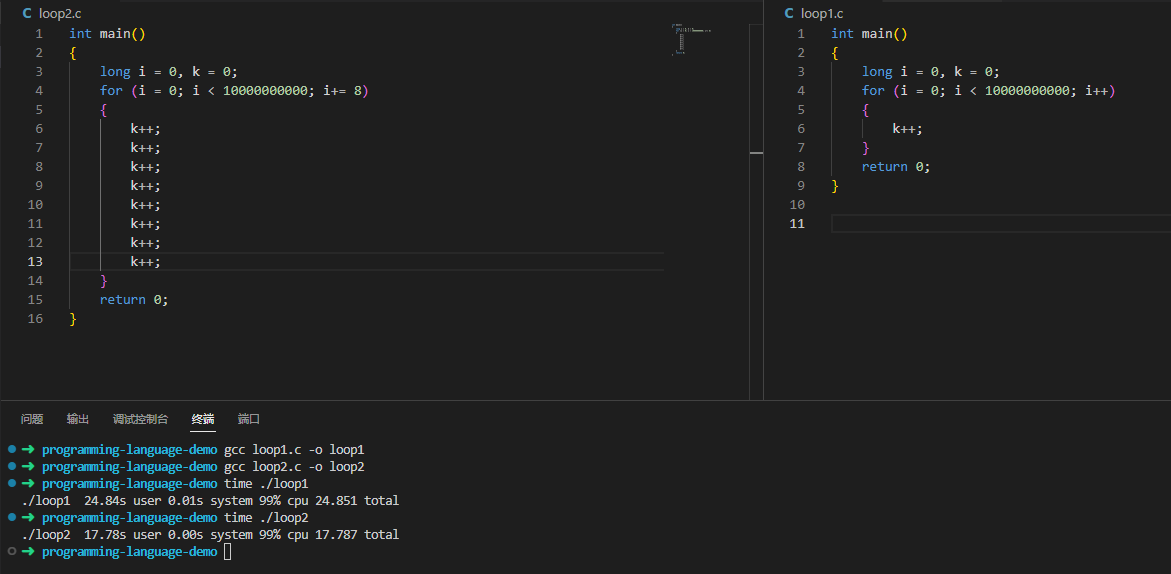
做同样的事情,通过循环展开优化,所消耗时间直接从25.4秒降到了17秒!
首次优化
先把每次循环内拷贝字节的个数,由1个提高到到8个,这样就可以把迭代次数降低8倍。
先假设,send()函数的参数count总是8的倍数,那么上面的代码就可以修改为:
void send_1(uint8_t *to, uint8_t *from, uint16_t count)
{
uint16_t n = count / 8; /*假设count是8的倍数*/
do
{
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
} while (--n > 0);
}就是把原来迭代里的操作复制了8次,然后把迭代次数降低到了8倍。.
如果不是8的整数倍呢:
void send_2(uint8_t *to, uint8_t *from, uint16_t count)
{
uint16_t n = count / 8;
do
{
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
*to++ = *from++;
} while (--n > 0);
n = count % 8;
while (n-- > 0)
{
*to++ = *from++;
}
}C语言switch-case的一些特性
C语言中switch-case语句的一些特性:
case语句后面的break语句不是必须的。
在switch语句内,case标号可以出现在任意的子语句之前,甚至运行出现在if、for、while等语句内。
利用switch-case的特性,用来处理第一个while循环之后仍然剩余的count % 8个字节的数据。于是便有了这样的代码:
void fast_copy(uint8_t *to, uint8_t *from, uint16_t count)
{
uint16_t n = (count + 7) / 8;
switch (count % 8) {
case 0: do { *to++ = *from++;
case 7: *to++ = *from++;
case 6: *to++ = *from++;
case 5: *to++ = *from++;
case 4: *to++ = *from++;
case 3: *to++ = *from++;
case 2: *to++ = *from++;
case 1: *to++ = *from++;
} while (--n > 0);
}
}假设count = 20,那么:
n = (count + 7) / 8 = 27 / 8 = 3
count % 8 = 4所以:
switch语句会落入case 4的标签内,然后依次执行了case 4、3、2、1四条语句。自此之后,其实就跟switch-case语句再也没有关系了。
while语句判断--n > 0,条件成立,于是跳转到case 0进入循环体执行,于是依次执行case 0、7、6、5、4、3、2、1一共8条语句。此时n = 2.
再次进入while语句处判断--n >0,条件成立,再次跳转到case 0处进入循环体执行。此时n = 1。
此时,while语句处判断--n >0,条件失败,退出循环,函数结束。
在上面的基础上,如果to指针也进行自增,则会得到一个效率非常高的拷贝函数,如果直接使用,则可以讲to设置为一个寄存器的地址,例如串口发送的寄存器。